SubmaoyanTop100()Url="http://maoyan.com/board/4?offset=0"'猫眼电影top100网址SetoHttp=CreateObject("MSXML2.ServerXMLHTTP")'创建一个xmlhttp对象SetoDom=CreateObject("htmlfile")'创建一个Dom对象 'XmlHttp对象(MSXML2.XMLHTTP)向http服务器发送请求并使用微软XML文档对象模型Microsoft® XML Document Object Model (DOM)处理回应。 WithoHttp'open,创建一个新的http请求,并指定此请求的方法、URL以及验证信息(用户名/密码)'send,发送请求到http服务器并接收回应.Open"GET",Url,False'使用Open方法,用get请求,False代表非异步加载.send'将open方法的信息发送给网页服务器oDom.body.innerHtml=.responseText'将响应网页的HTML赋值给Dom对象,并只需要body标签里面的内容EndWithEndSub
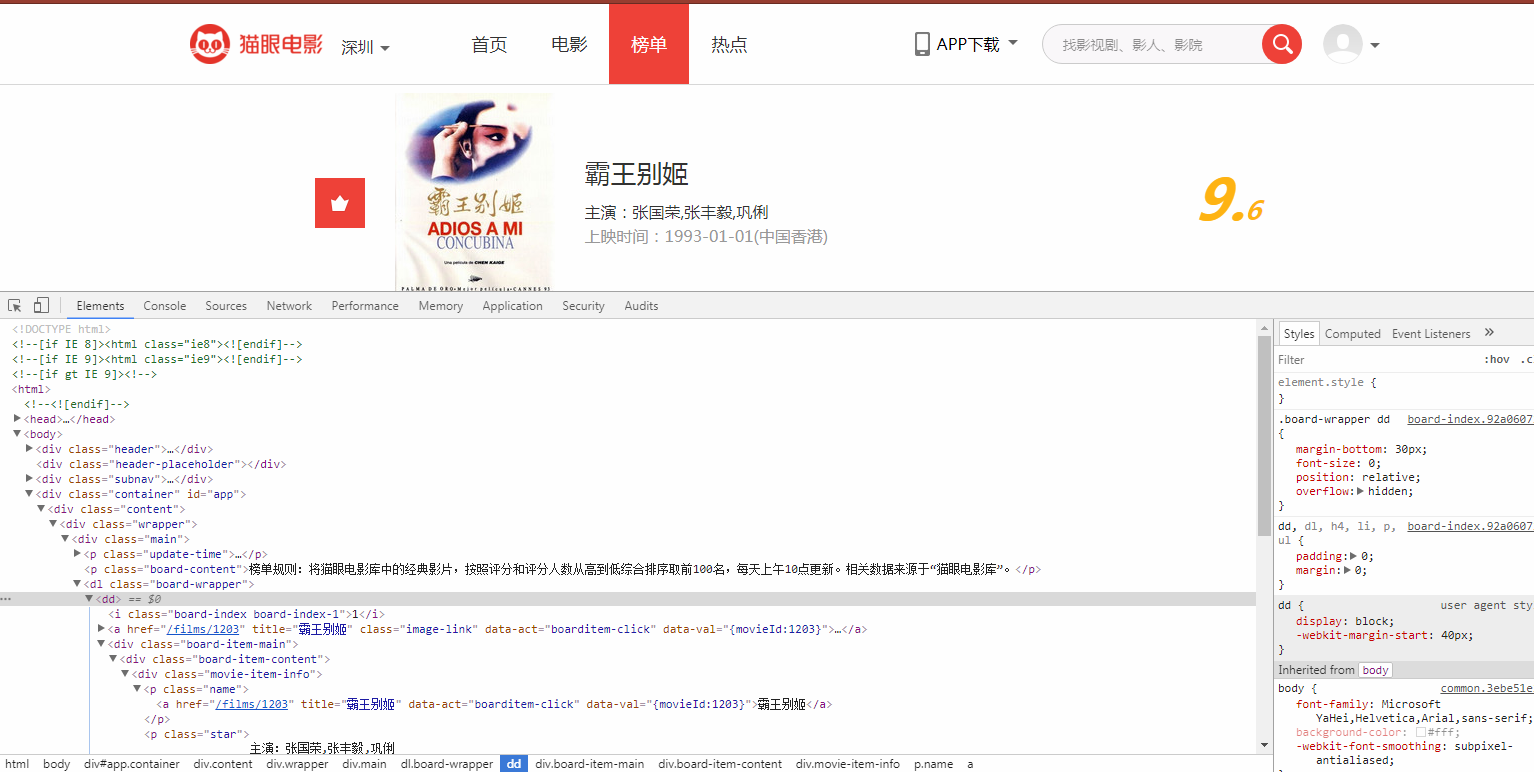
2.接下来我们要将oDom里面的信息给提取出来
此图截图于网易晕课堂方骥老师的vba课
通过对网页源代码的分析,可以发现,每部电影的信息隐藏在<dd>...</dd>这个标签里的
接下来我们就可以这样子写
Sub maoyanTop100()
Url = "http://maoyan.com/board/4?offset=0" '猫眼电影top100网址
Set oHttp = CreateObject("MSXML2.ServerXMLHTTP") '创建一个xmlhttp对象
Set oDom = CreateObject("htmlfile") '创建一个Dom对象
'XmlHttp对象(MSXML2.XMLHTTP)向http服务器发送请求并使用微软XML文档对象模型Microsoft® XML Document Object Model (DOM)处理回应。
With oHttp
'open,创建一个新的http请求,并指定此请求的方法、URL以及验证信息(用户名/密码)
'send,发送请求到http服务器并接收回应
.Open "GET", Url, False '使用Open方法,用get请求,False代表非异步加载
.send '将open方法的信息发送给网页服务器
oDom.body.innerHtml = .responseText '将响应网页的HTML赋值给Dom对象,并只需要body标签里面的内容
End With
i = 2
For Each Item In oDom.all
If Item.tagname = "DD" Then
Range("a" & i) = Item.Children(1).getAttribute("title") '电影名信息
Range("b" & i) = Item.Children(2).Children(0).Children(0).Children(1).innerText '主演
Range("c" & i) = Item.Children(2).Children(0).Children(0).Children(2).innerText '上映时间和国家
Range("d" & i) = Item.Children(2).Children(0).Children(1).Children(0).innerText '评分
i = i + 1
End If
Next
End Sub
Sub maoyanTop100()
i = 2
For n = 0 To 9
Url = "http://maoyan.com/board/4?offset=" & n * 10
Set oHttp = CreateObject("MSXML2.ServerXMLHTTP")
Set oDom = CreateObject("htmlfile")
With oHttp
.Open "GET", Url, False
.send
oDom.body.innerHtml = .responseText
End With
For Each Item In oDom.all
If Item.tagname = "DD" Then
Range("a" & i) = Item.Children(1).getAttribute("title")
Range("b" & i) = Item.Children(2).Children(0).Children(0).Children(1).innerText
Range("c" & i) = Item.Children(2).Children(0).Children(0).Children(2).innerText
Range("d" & i) = Item.Children(2).Children(0).Children(1).Children(0).innerText
i = i + 1
End If
Next
Next n
MsgBox "Done !"
End Sub


沒有留言:
張貼留言